High-Performance Engineering
Big Data is messy. We build distributed, AI-enhanced pipelines to transform billions of data points into visual insights in real time. Here are some examples from our blog below.

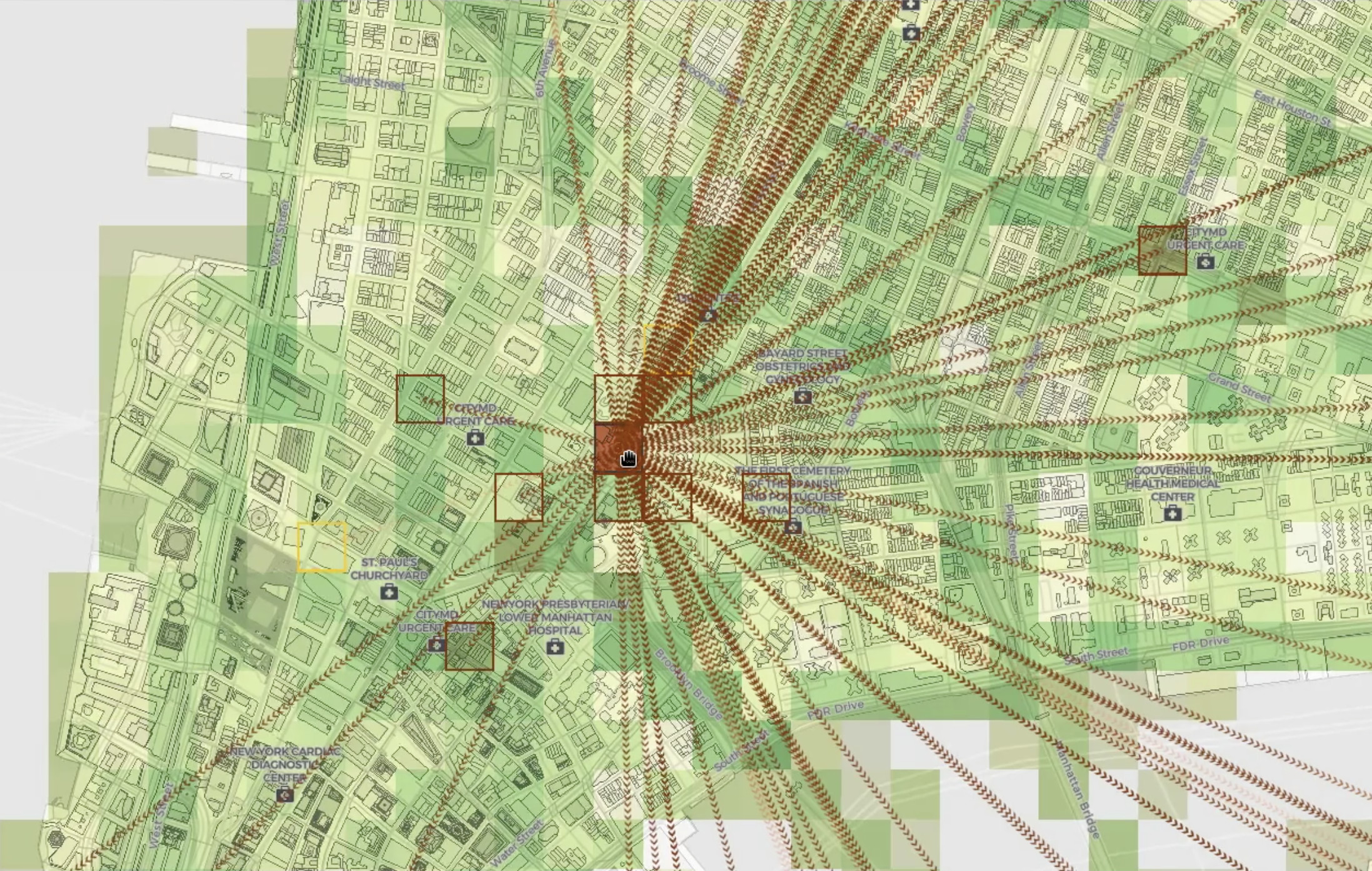
Many are wondering what more can be done to contain further outbreaks while a socially distanced world undertakes the time-consuming process of building immunity. We experimented to see how we might enable visualization tools for outbreak analysis.

An Uncharted research product for the visual analysis of massive graph data is featured in the pages and on the cover of the latest issue of Information Visualization, a leading peer-reviewed journal on the study and application of information visualization.
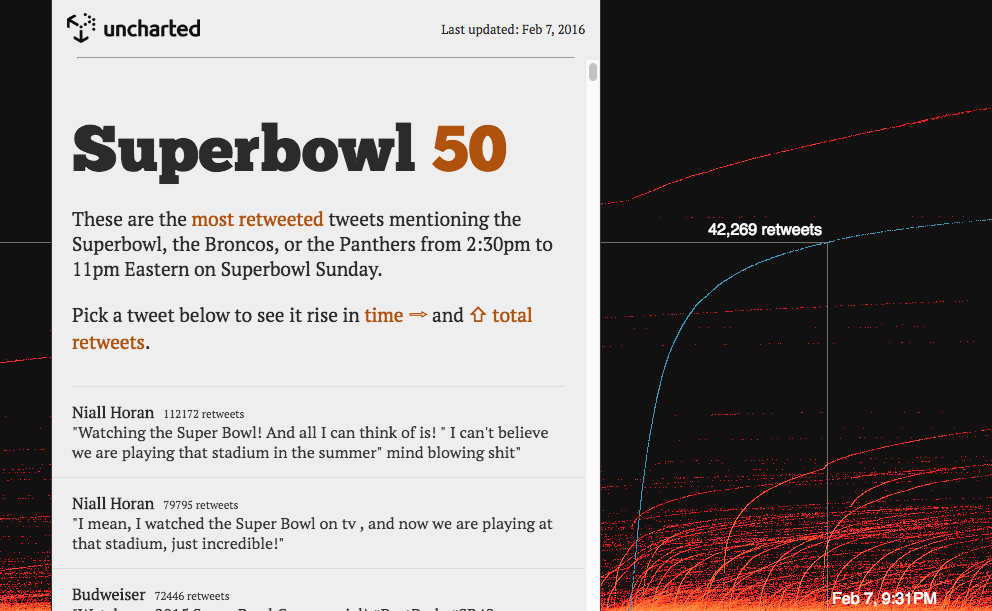
Last summer we began tracking tweets that mention Donald Trump in preparation for our talk at Strata NY. We’ve continued monitoring the topic and, as of March 3rd 2016, we’ve processed over 91 million tweets.
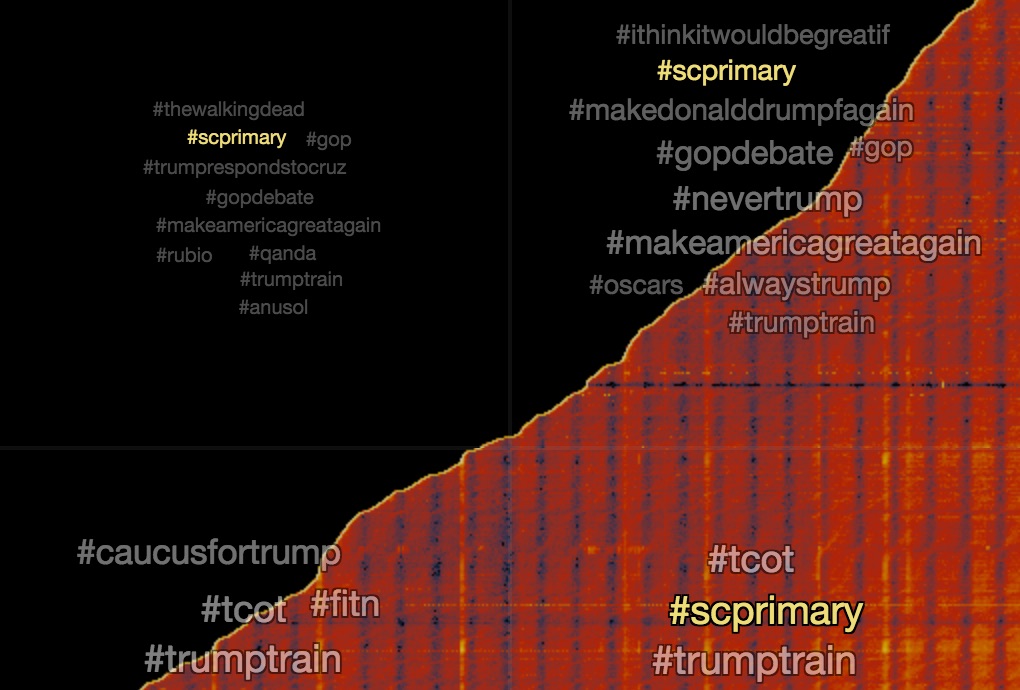
In our ongoing analysis of tweets about Donald Trump we pulled together 27 million tweets in the month of February from 3.7 million unique users. It seems like everyone is joining the conversation in different ways.