Technology
Blog
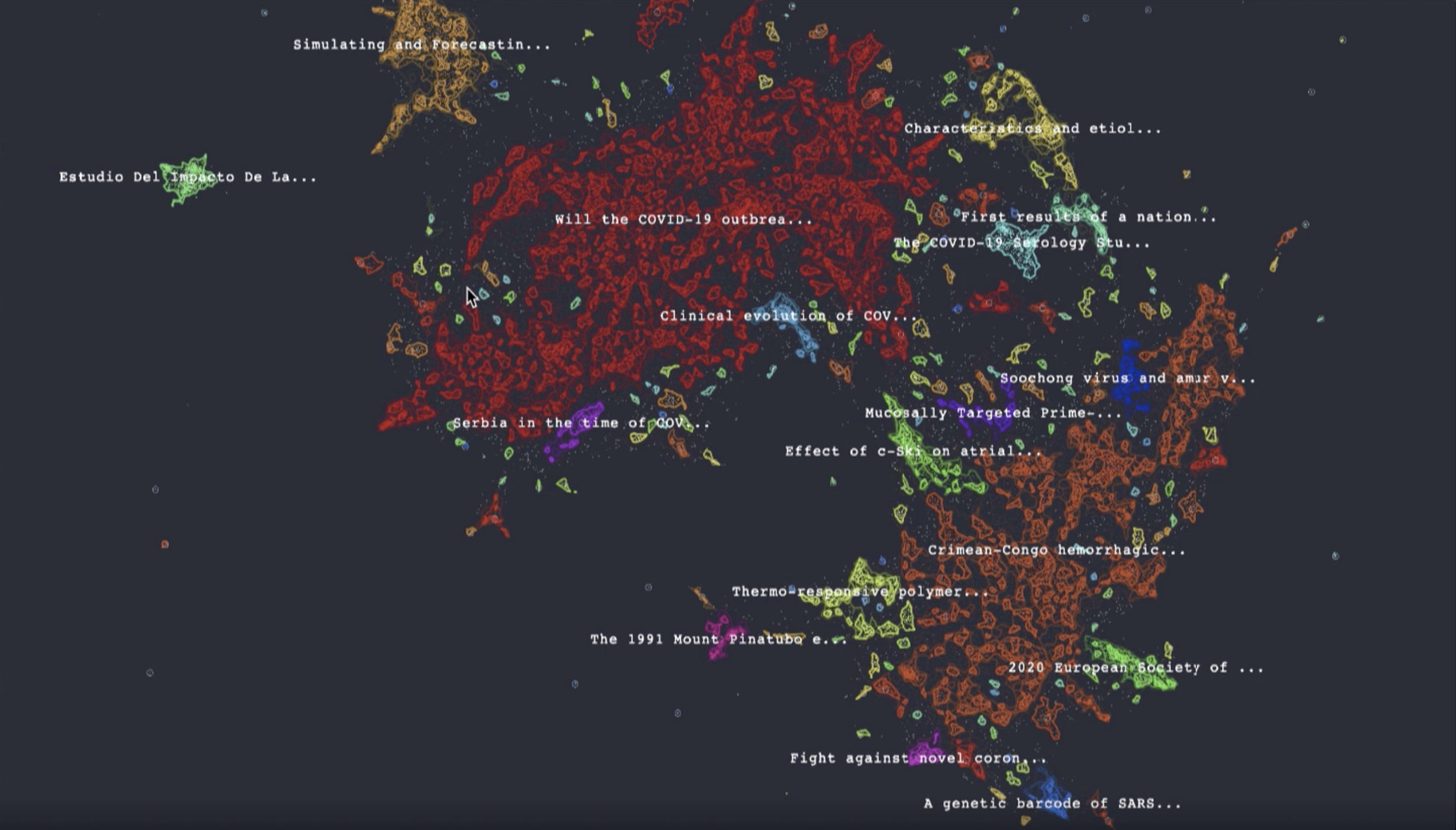
Uncharted at IEEE VIS 2021
It’s time again for IEEE VisWeek, and Uncharted is excited to be on hand both as a sponsor of the VIS Diversity/Inclusivity Scholarships and a presenter of three new peer-reviewed research papers.
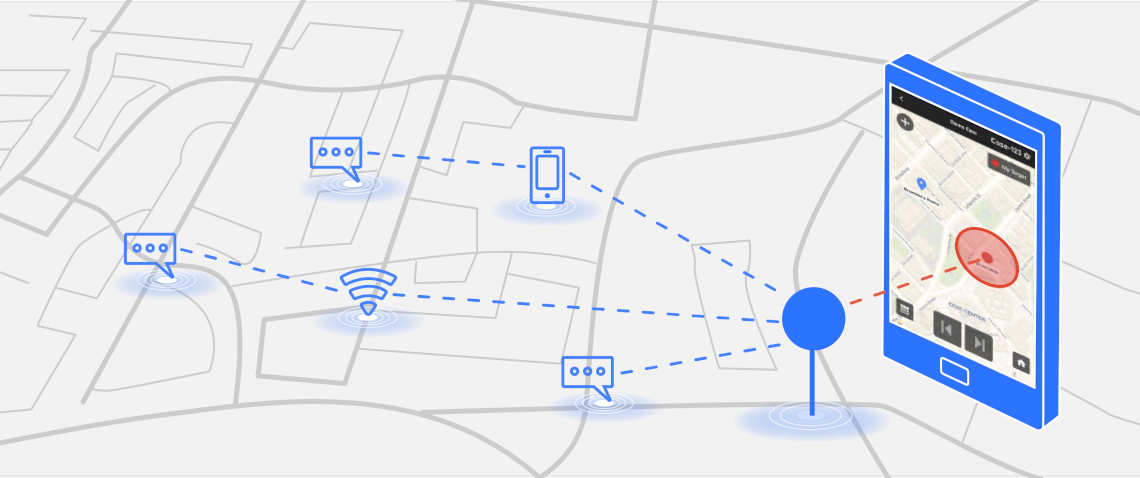
We’re excited to introduce GeoTime Live, a new crime-fighting tool that lets investigators use any device to instantly map live ping emails. GeoTime Live has already been successfully used in exigent scenarios for cases related to narcotics, homicide, fugitive, kidnappings, Amber Alerts, Silver Alerts, despondents and dispatch.
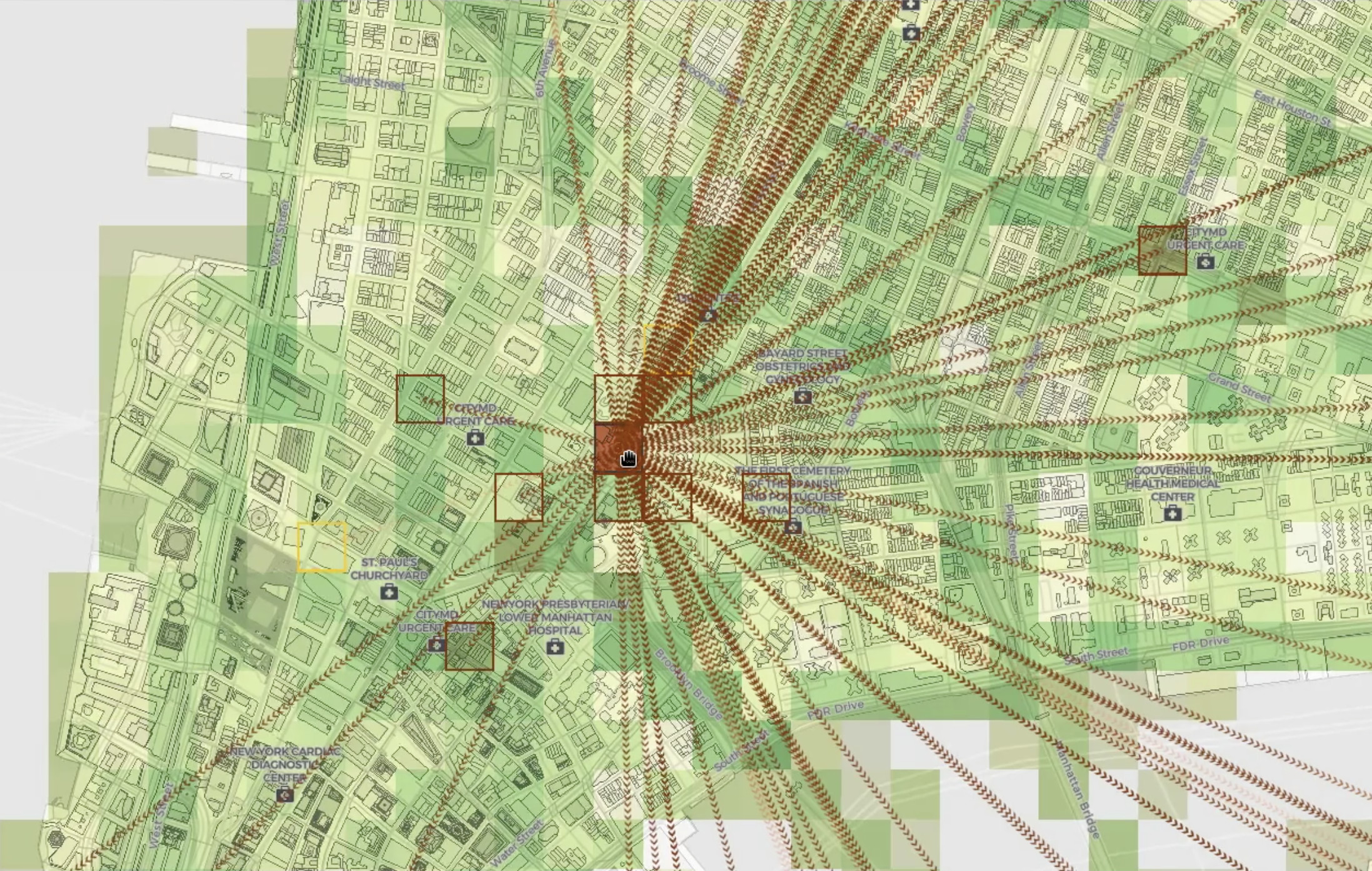
Many are wondering what more can be done to contain further outbreaks while a socially distanced world undertakes the time-consuming process of building immunity. We experimented to see how we might enable visualization tools for outbreak analysis.

Despite the many unforeseen challenges of 2020, it has been another year of exciting new firsts at Uncharted.
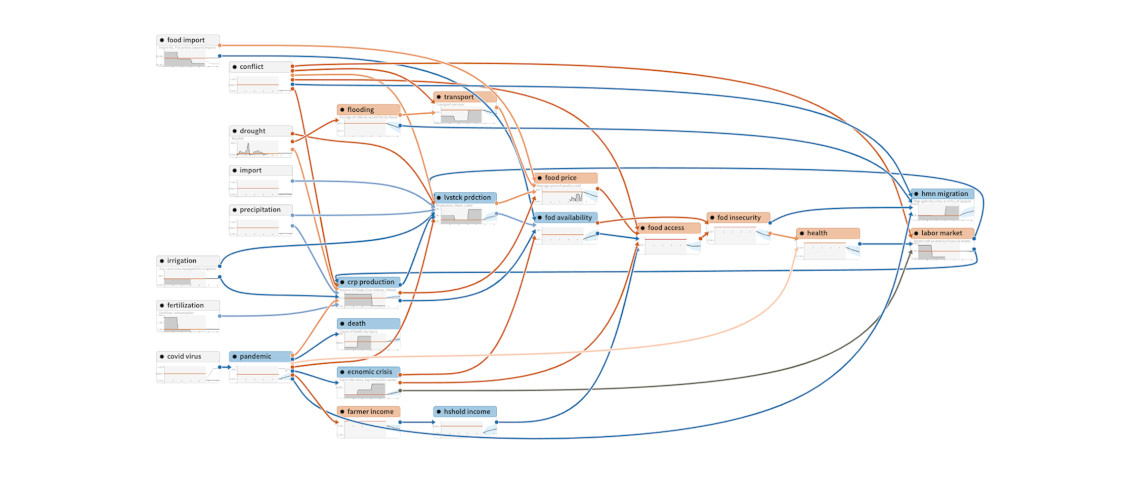
This seminar describes the visualization and augmented intelligence techniques being developed by Uncharted for interactively exploring, assembling and engaging large, complex graphical models.